
如何将用户输入映射到预定义的意图类别,如直接调用大模型、联网搜索、工具调用?
1 概述
区分两种不同类型的意图识别:
- 系统路由型意图识别(或称语义路由):对话系统首先判断用户请求应由哪种处理模块来响应,如直接让大语言模型回答、调用搜索引擎检索、或者调用某个特定工具来处理。其核心目标是路由:将用户的自然语言查询分发到最合适的子系统或知识源,从而获得最优的答案。
- 任务导向型意图识别是传统任务型对话中的概念,其目的是判断用户的具体目标或意图类别,例如用户想“预订航班”还是“查询天气”等。这种识别往往发生在对话的自然语言理解模块,用于将用户语句映射到预定义的任务类别,并识别所需的槽位信息。
本次调研针对的任务场景是:
- 分类任务:将用户输入映射到预定义的意图类别(直接调用大模型、联网搜索、工具调用)
2 主流方法
2.1 规则匹配
简单地依据关键词或模式判断。如包含关键词“新闻”就路由到“联网搜索”。
2.2 监督分类器
传统上(2023年及以前),意图检测系统是使用有监督分类或基于相似性的模型构建的。
先用标注数据训练分类模型对意图进行预测,然后根据预测结果路由。
SetFit(Sentence Transformer Fine-tuning)(2022.09.22)
两阶段训练过程:
- 首先在少量标注样例 (典型值是每类 8 个或 16 个样例) 上微调一个 Sentence Transformer 模型。
- 然后用微调得到的 Sentence Tranformer 的模型生成文本的嵌入 (embedding) ,并用这些嵌入训练一个分类头 (classification head) 。
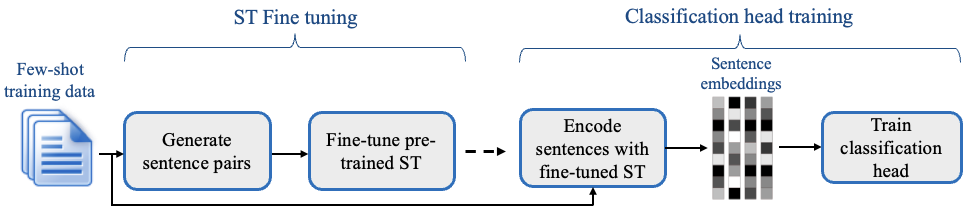
SetFit 仅需8个样本(few-shot learing)即可达到与在全量数据(3k个样本)微调RoBERTa Large相当的准确度,且训练和推理速度快得多。此外,还有传统的BERT/XLNet微调方法,以及LSTM+注意力等。
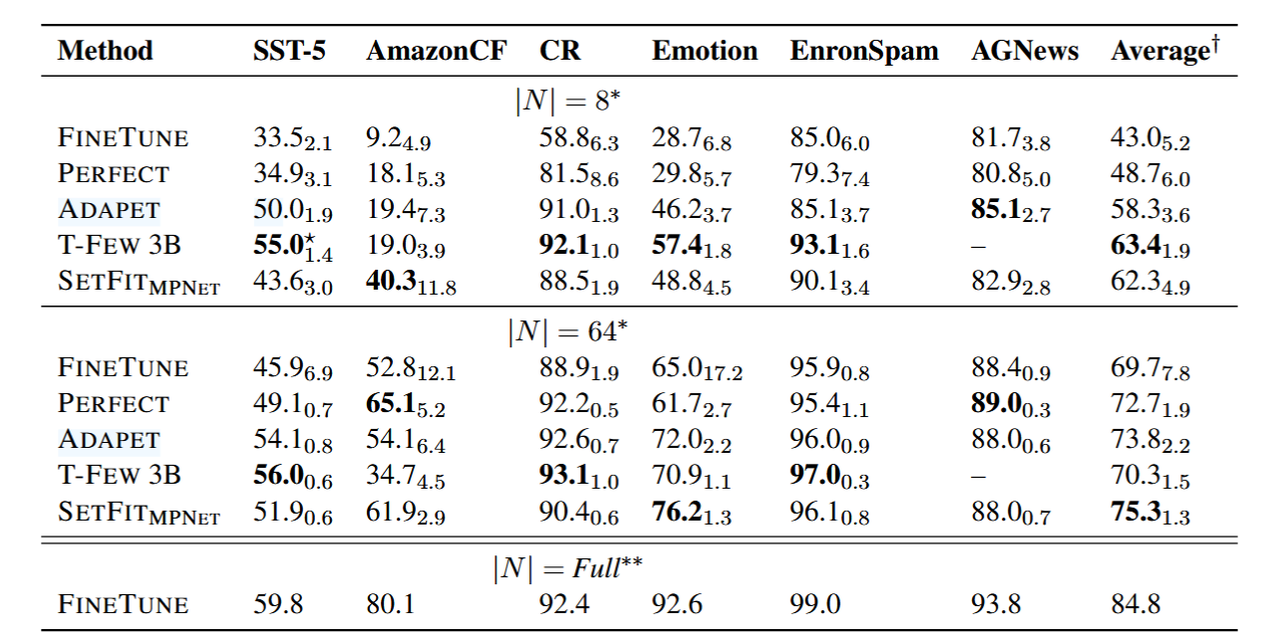
RAFT 排行榜上表现突出的方法 (截至 2022 年 9 月):
| Rank | Method | Accuracy | Model Size |
| 2 | T-Few | 75.8 | 11B |
| 4 | Human Baseline | 73.5 | N/A |
| 6 | SetFit (Roberta Large) | 71.3 | 355M |
| 9 | PET | 69.6 | 235M |
| 11 | SetFit (MP-Net) | 66.9 | 110M |
| 12 | GPT-3 | 62.7 | 175 B |
无需提示词、训练快、调用成本低,在二分类小样本任务尤其强。
ModernBERT 分类器
《When to Reason: Semantic Router for vLLM》(2025.10.09)
- vLLM:LLM 的推理和服务引擎,可以加速和优化现有 LLM 的推理过程。
- 工作流程:用户输入被编码器转化成语义向量,通过监督分类器(一个完全微调的 Transformer 网络)将向量分类为简单查询型或推理密集型。
- 训练模式:全监督/传统微调 (Full Supervised Fine-tuning)
- 模型架构:BERT-Style Cross-Encoder (Encoder-Only)
- 数据集:
- MMLU-Pro (Multi-task Language Understanding - Professional):用于意图分类器的训练和最终系统的评测 。它包含大约 12,000 个跨越约 14 个领域的学术样本。
- Microsoft Presidio:包含约 50,000 个 Token 级别的 PII(个人身份信息)示例,用于意图分类器的训练。
- Jailbreak Security Datasets:用于意图分类器的训练,以增强其对安全相关的分类能力。
- 评测结果:使用 Qwen/Qwen3-30B-A3B 模型在 vLLM v0.10.1 上进行。语义路由器在 MMLU-Pro 上的整体准确率提高了 10.24 个百分点,同时将延迟和 Token 消耗降低了近 50%。
| 方法 (Method) | 平均准确率 (Avg. Accuracy) | 平均延迟 (Avg. Latency, s) | 平均 Tokens (Avg. Tokens) |
| 语义路由器 (Semantic Router) | 58.57% [cite: 137] | 13.09 [cite: 137] | 887.5 [cite: 137] |
| 直接 vLLM (Direct VLLM) | 48.33% [cite: 137] | 24.76 [cite: 137] | 1,722.1 [cite: 137] |
| 提升幅度 (Improvement) | +10.24pp (百分点) [cite: 137] | -47.1% [cite: 137] | -48.5% [cite: 137] |
两种模型的对比:
| 方面 | SetFit | ModernBERT |
|---|---|---|
| 实现目标 | 高效的少样本学习(Few-Shot Learning)。 | 高性能、高准确率的全监督分类。 |
| 实现方法 | 解耦:微调嵌入模型 + 训练线性分类器。 | 耦合:端到端微调整个 Transformer 编码器。 |
| 规模与效率 | 分类头极小(线性模型),推理速度快,适合资源有限或快速迭代。 | 分类头深度耦合于庞大的 Transformer 结构,推理准确性高,适合对精度要求极高的生产环境。 |
2.3 向量语义路由
预先为每种路由定义示例句,将用户查询编码为向量,与示例向量比对,选择最近邻路由。
非常适用于有一组确定的意图类别,并且需要极快的路由和极高的吞吐量的场景。
开源项目 semantic-router(Github star 2.9k)
将用户输入和预先定义的路由描述(或“语料”)转换为向量嵌入,然后计算相似度。
流程:
- 定义路由和示例提示
- 将它们加载到
RouteLayer。 - 然后在运行时调用
RouteLayer.route(query)获取最佳匹配的路由名称。
- 优点:引入便捷、路由快速。一旦路由向量预先计算好,对新查询进行分类只需快速查找嵌入向量,非常适合高吞吐量或低延迟的需求。
- 缺点:需要为每个意图准备代表性语句。其准确性取决于这些示例对查询变化的捕捉程度。如果用户的措辞与所有示例相差甚远,路由器可能会错误路由。此外,语义路由是静态类别;处理动态或嵌套意图可能更加困难。
- 在实践中,许多团队对领域中稳定、定义明确的部分使用语义路由,而对任何“其他”或未分类的内容则回退到 LLM 或默认代理。
Langchain.EmbeddingRouterChain
Langchain 提供了EmbeddingRouterChain ,用向量搜索做路由。
首先定义所有意图的“名称+描述”对,并用句子嵌入模型编码到内存向量库;用户输入的文本经同一嵌入模型编码后,与库中意图嵌入做相似度检索,选择相似度最高的意图对应的下游Chain。
2.4 提示词驱动
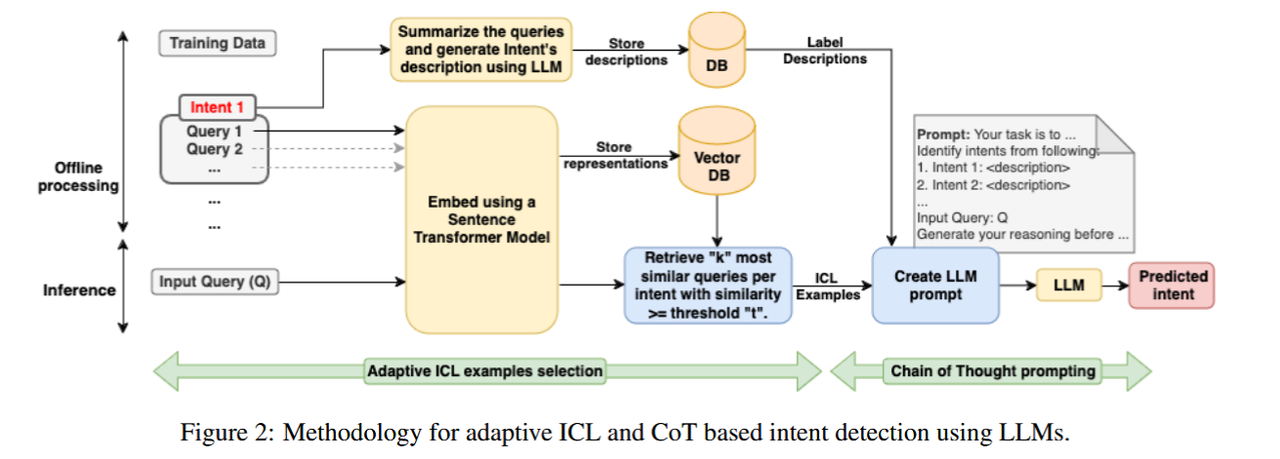
《Intent Detection in the Age of LLMs》(2024.10.02):使用大模型的自适应上下文学习(adaptive in-context learning, ICL)和思维链(chain-of-thought, CoT)提示法改进意图识别。与通过对比微调设定的句向量分类器 SetFit 模型相比,预测质量和延迟方面的表现更优。
- 自适应ICL:系统会将在推理阶段收到的用户查询与一个向量数据库中的训练查询嵌入进行比较,然后检索 k 个最相似的查询作为 ICL 示例,这些示例随后被用来构建 LLM 的提示,以帮助 LLM 更好地检测新查询的意图。(提供示例教模型)(GPT-3)
- CoT:一种提示技术。给 LLM 的提示中包含一条指令,要求它在给出最终答案之前先”生成你的推理”(Generate your reasoning before…)。这种方法促使 LLM 在输出最终的“预测意图” 之前,先一步一步地生成其思考过程,从而提高其准确性。(引导模型生成推理过程)
LangChain提供了
LLMRouterChain,用 LLM 做路由;
2.5 混合策略
- 《Intent Detection in the Age of LLMs》进一步提出混合系统(SetFit+LLM):
- 用户查询先被送到SetFit模型,该模型通过微调来执行分类任务,非提示词驱动。
- 采用基于不确定性(蒙特卡洛 Dropout)的路由策略,在SetFit不确定时,调用LLM(使用自适应ICL+CoT)进行意图检测。
评测结果:
| 方法类别 | 最佳代表模型 (或配置) | 平均 F1 Score | 平均 p50 延迟 (s) | OOS Recall (范围外召回) | 总结 |
|---|---|---|---|---|---|
| LLMs | Claude v3 Haiku | 0.736 | 1.697 | 论文指出 OOS Recall 表现普遍较差 | 在预测准确性(F1 Score)上表现最优,但推理延迟最高,泛化能力强于 SetFit。 |
| SetFit | SetFit + Neg Aug (SNA) | 0.658 | 0.03 | 具有极低的延迟(比 LLM 快约 56 倍),通过负样本增强(Neg Aug)性能得到显著提升,但泛化能力相对较弱。 | |
| 混合系统 | SetFit + Neg Aug + LLM (通过不确定性路由) | 接近 LLM 性能 | 降低 50% | 实现了性能和效率的最佳权衡,在保持接近 LLM 准确度的同时,将延迟降低了一半。 | |
| 即混合系统可在近似不损失准确率的前提下,显著降低 50%以上的计算延迟。 |
- AWS 提出 LLM 辅助路由(LLM-assisted routing) + 语义路由(Semantic routing),使用语义搜索进行初步的广泛分类或领域匹配,然后使用 LLM 在这些广泛类别中进行更细粒度的分类。
2.6 横向对比
| 方法 | 优点 | 缺点 | 最佳使用场景 |
|---|---|---|---|
| 规则匹配 | 快、可解释、无推理成本 | 维护难、覆盖差、语义弱 | 小规模、确定性业务 |
| 监督分类器 | 高准确、低延迟、少样本可用 | 新意图需重训、泛化差 | 稳定系统主路由 |
| 语义向量路由 | 扩展灵活、零样本支持、吞吐高 | 精度依赖embedding、边界模糊 | 工具/API分发,多意图 |
| LLM提示词 | 精度最高、处理复杂语义强 | 成本高、延迟高、不稳定 | 困难/长尾意图兜底 |
| 混合策略 | 性价比最高、性能稳健 | 系统更复杂 | 生产级最佳实践 |
3 企业应用
3.1 Anthropic Claude
倾向于先使用基于模型推理的“agentic search”,必要时才用检索。
语义搜索通常比代理搜索更快,但准确性较低、维护难度较大且透明度较低。它涉及将相关上下文“分块”,将这些分块嵌入为向量,然后通过查询这些向量来搜索概念。鉴于其局限性,我们建议先从代理搜索开始,仅在需要更快的结果或更多变体时才添加语义搜索。
3.2 Google Gemini
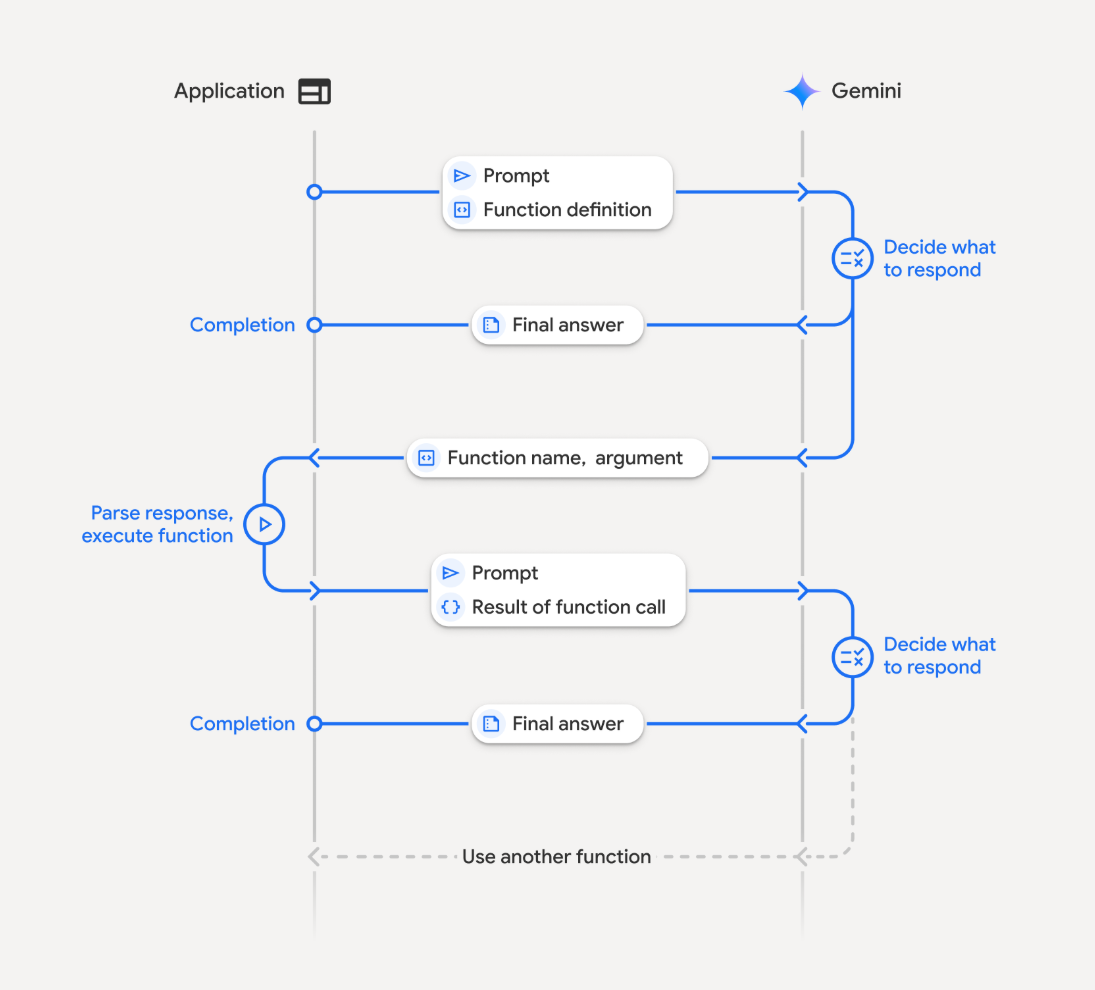
通过 Function Calling 增强意图识别。Function Calling 本质上是一种结构化的输出格式。
- 清晰的意图边界:向LLM提供清晰的函数签名和描述,要求LLM返回的意图标签是具体的函数名。提供了结构化和高保真度的 ICL 样本。
- 双重约束:
- 意图识别(选择函数)
- 槽位填充(提取参数)
- 输出是结构化的 JSON 对象,而非自然语言。将意图识别的结果从“意图标签”提升到“可执行的指令”。
参考资料:
- Setfit https://github.com/huggingface/setfit
- Efficient Few-Shot Learning Without Prompts http://arxiv.org/abs/2209.11055
- SetFit: 高效的无提示少样本学习 https://huggingface.co/blog/zh/setfit
- When to Reason: Semantic Router for vLLM http://arxiv.org/abs/2510.08731
- Intent Recognition and Auto‑Routing in Multi-Agent Systems https://gist.github.com/mkbctrl/a35764e99fe0c8e8c00b2358f55cd7fa
- semantic-router
- Intent Detection in the Age of LLMs https://arxiv.org/abs/2410.01627v1
- Multi-LLM routing strategies for generative AI applications on AWS https://aws.amazon.com/cn/blogs/machine-learning/multi-llm-routing-strategies-for-generative-ai-applications-on-aws/#:~:text=
- Building agents with the Claude Agent SDK https://www.anthropic.com/engineering/building-agents-with-the-claude-agent-sdk
- Function calling with the Gemini API https://ai.google.dev/gemini-api/docs/function-calling?example=meeting#how-it-works